Come creare un linguaggio di programmazione
Molti sviluppatori, si pongono questa domanda: “Come progettare un linguaggio di programmazione?”, oppure, “Cosa si nasconde dietro un comando di un qualsiasi linguaggio?”. Leggi questo articolo e capirai come sviluppare un interprete tutto tuo.
di Antonio Lamorgese
Molti programmatori, durante il loro percorso professionale, si trovano a dover utilizzare svariati linguaggi di programmazione, e spesso a sfruttare tecniche e algoritmi, a volte anche molto sofisticati, per la risoluzione di problematiche che via via si manifestano. Durante tale percorso, molti di loro, si pongono questa domanda: “Come creare un linguaggio di programmazione?”, oppure, “Cosa si nasconde dietro un comando di un qualsiasi linguaggio?”.
Prima di rispondere a questa domanda, cercheremo di capire quanti tipi di linguaggi di programmazione esistono.
Oggi, abbiamo due tipologie di linguaggi, esistono linguaggi compilati e linguaggi interpretati, la differenza è sostanziale. Nei linguaggi compilati, il codice sorgente cioè il nostro programma, viene convertito in un file eseguibile direttamente dalla macchina senza l’ausilio di nessun software di traduzione intermedio. Nei linguaggi interpretati invece, il nostro sorgente, non viene convertito in un file eseguibile ma, tradotto comando per comando ed eseguiti di volta in volta da un programma intermedio chiamato interprete.
Riepilogando possiamo dire che, nei linguaggi compilati, il codice sorgente viene convertito, da un software chiamato compilatore, in un file eseguibile direttamente dal computer senza l’ausilio di altri strumenti. Mentre, in un linguaggio interpretato, il codice presente all’interno di un file sorgente viene eseguito da un software chiamato interprete.
In questo articolo ti spiegherò come creare un linguaggio di programmazione, nello specifico un interprete, in quanto “più semplice ed immediato” della progettazione di un compilatore, che richiederebbe non solo una conoscenza approfondita di alcuni strumenti molto sofisticati, che vedremo, ma anche una conoscenza avanzata del tipo di processore che dovrà eseguire il codice.
Ma cosa sarai in grado di fare dopo la lettura di questo articolo? Beh, capirai l’uso di un Lexer e di un Parser, come programmarli fino a progettare una tua propria shell dei comandi e alla creazione di uno dei comandi essenziali per qualsivoglia linguaggio: “il comando Print”. Insomma scoprirai come creare comandi, passare loro parametri ed eseguirli all’interno della Shell di comandi, che progetterai e personalizzerai a tuo piacimento. Non solo ma vedrai anche come eseguire questi comandi salvandoli all’interno di uno script tramite un interprete progettato ad hoc per l’occasione.
Indice del Post...
1. Software necessari
Come ogni progetto che si rispetti, abbiamo bisogno di scaricare il necessario, cioè allestire la nostra cassetta degli attrezzi. Per poter configurare l’ambiente di progettazione, indispensabile per tale scopo, abbiamo bisogno di alcuni software speciali. Fortunatamente i software che utilizzeremo sono tutti open source, cioè scaricabili e utilizzabili gratuitamente. Questi software sono disponibili per i più diffusi Sistemi Operativi, pertanto quello che vedremo in questo articolo non è orientato ad uno specifico sistema operativo ma, è applicabile sia a sistemi Windows che Linux.
1.1 Editor di testi
Dato che avremo bisogno di editare file di testo, abbiamo bisogno necessariamente di un editor di testi. Tra i tanti disponibili in rete, ti consiglio Visual studio Code, l’editor della Microsoft, gratuito e dalle ottime caratteristiche, ideale per ogni linguaggio e progetto software.
Per scaricare Visual Studio Code vai a questo link dove potrai scegliere il pacchetto per il S.O. desiderato e procedere con l’installazione, come mostrato in figura:
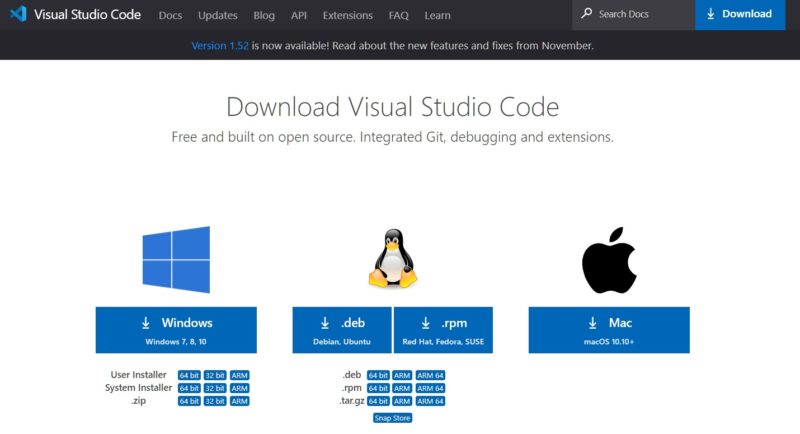
Questo editor non ha bisogno, per la nostra esigenza, di configurazione o personalizzazione ma qui trovi un video esplicativo del processo di download e installazione di Visual Studio Code.
Ad ogni modo, per questa tipologia di progetto, non sei obbligato ad utilizzare per forza Visual Studio Code ma puoi scegliere tra tante altre alternative open source disponibili, e qui trovi gli editor di testo più utilizzati dagli sviluppatori.
1.2 Compilatore linguaggio C
Un altro tool necessario è un compilatore del linguaggio C, noi utilizzeremo MinGW. MinGW è il porting in ambiente Windows del famoso compilatore GCC per Linux.
Solo e soltanto se usi Windows, devi scaricare il compilatore C MinGW da questo link, per Linux non c’è bisogno, lo installeremo con un semplice comando da terminale, come vedremo più avanti.
Successivamente, sempre e solo in Windows, estrai, copia e incolla la cartella mingw in C:, aggiorna la variabile di sistema PATH seguendo questi semplici passaggi:
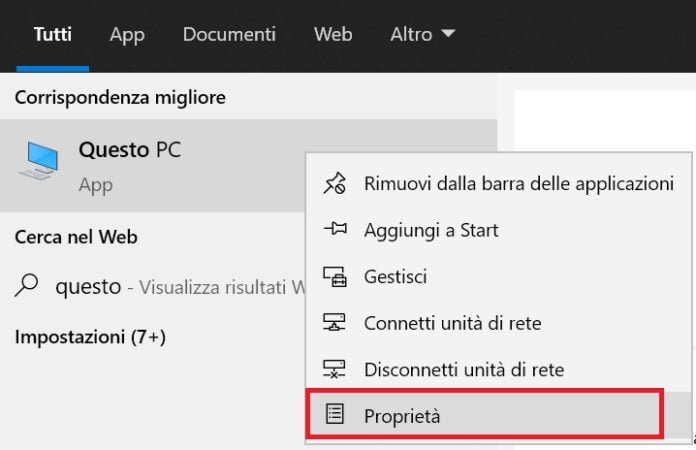
Per prima cosa clicca con il tasto destro del mouse sulla voce “Questo PC” e successivamente su “proprietà”, come in figura:
Clicca sulla voce “Impostazioni di sistema avanzate” e poi su “variabili d’ambiente”, come in figura:
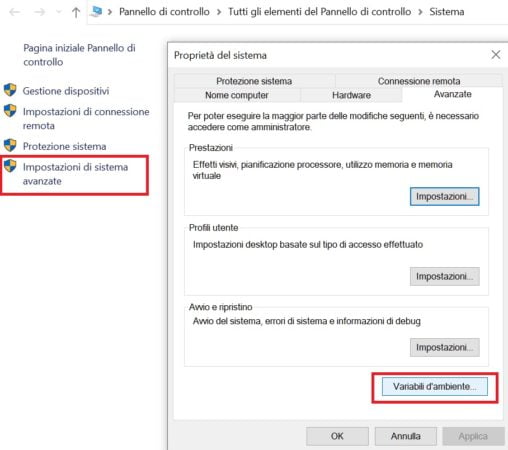
Seleziona, nel riquadro in basso relativo alle variabili di sistema, la riga che evidenzia il contenuto della variabile path, e poi clicca su modifica, come in figura:
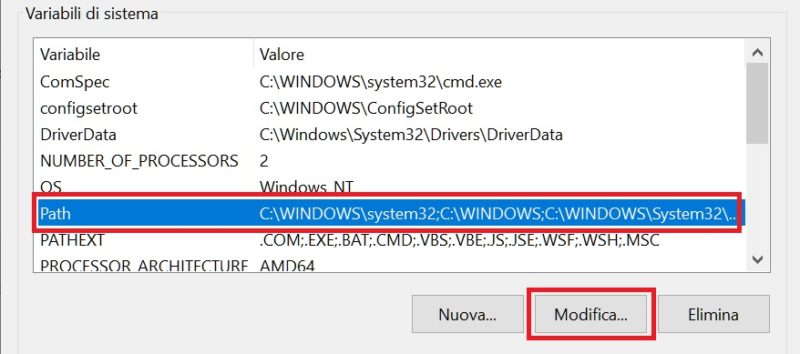
Clicca sul pulsante “Nuovo”, inserisci il seguente percorso: c:\mingw\bin, e successivamente su “Ok”, come in figura:
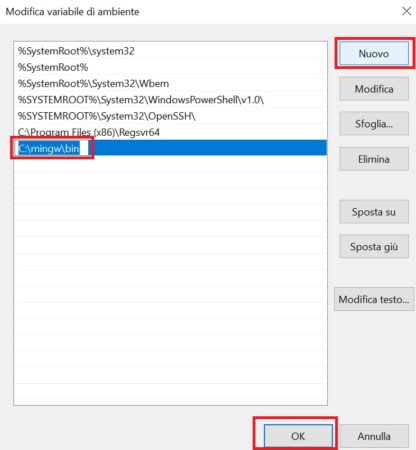
Riavvia il computer, per rendere effettive le modifiche apportate, alla variabile di sistema Path.
Per quanto riguarda l’installazione del compilatore C in Linux, le cose sono molto più semplici, questo significa che il tutto si riduce ad impartire il seguente comando da terminale: sudo apt-get install gcc.
1.3 Il Parser
Adesso è venuto il momento di installare un software che, farà da parte attiva, insieme al successivo che installeremo, parliamo di Bison. Sostanzialmente Bison è un software che analizza un flusso di dati, ricevuto dalla shell dei comandi o da uno script, al fine di riconoscere la grammatica di un comando o di un costrutto di un linguaggio di programmazione.
Attraverso Bison, genereremo il parser per il nostro interprete. Più avanti vedremo nel dettaglio come funziona, adesso limitiamoci ad installarlo.
Se disponi di un sistema Windows, non devi installare nulla, in quanto, Bison è già stato integrato nel pacchetto che hai scaricato al punto precedente. Ma se disponi di una distribuzione Linux, così come è avvenuto con il compilatore C, non devi fare altro che digitare il seguente comando da terminale: sudo apt-get install bison
Leggi anche: come installare windows 10 su raspberry Pi. 4 e Pi 3
1.4 L’analizzatore lessicale
Prima ho parlato di Bison come la parte attiva insieme ad un altro software, per la progettazione di un interprete. Quest’altro software è Flex. Flex è un analizzatore lessicale, cioè un generatore di scanner, in grado di analizzare un flusso dati, ricevuto dalla shell dei comandi o da uno script, al fine di riconoscere le keywords e i simboli, che compongono il nostro linguaggio, e compiere una determinata azione ogni volta che viene riconosciuta una combinazione di caratteri, chiamata TOKEN.
Tranquillo niente di complesso, adesso preoccupiamoci solo di installare Flex e successivamente capirai anche come funziona.
Ora, se possiedi un sistema Windows non devi installare nulla, in quanto Flex è già integrato, insieme a Bison e a MinGW, nel pacchetto che hai scaricato precedentemente. Ma se disponi di una distribuzione Linux, così come è avvenuto con il compilatore C e Bison, non devi fare altro che digitare il seguente comando da terminale: sudo apt-get install flex
2. Verifica della corretta installazione dei software
La nostra cassetta degli attrezzi è pronta, ma dobbiamo verificare che tutto quello che è stato appena fatto è funzionante e regolarmente configurato. Quindi, digita i seguenti comandi da prompt dei comandi di Windows o, da terminale Linux:
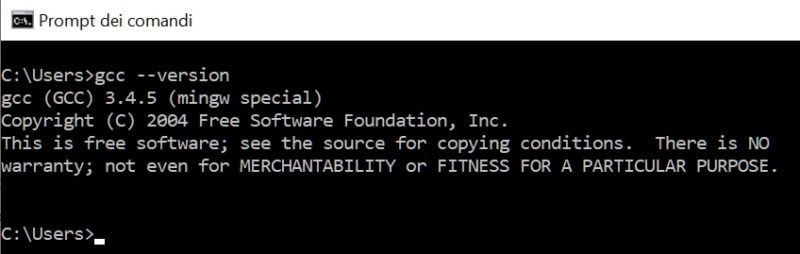
gcc –version
Premi Invio, in risposta se otterrai indicazioni, circa la versione di gcc installato, significa che il compilatore C è stato installato correttamente, come mostrato in figura:
bison –version
Premi Invio, in risposta se otterrai indicazioni, circa la versione di bison installata, significa che il generatore di Parser è stato installato correttamente, come mostrato in figura:
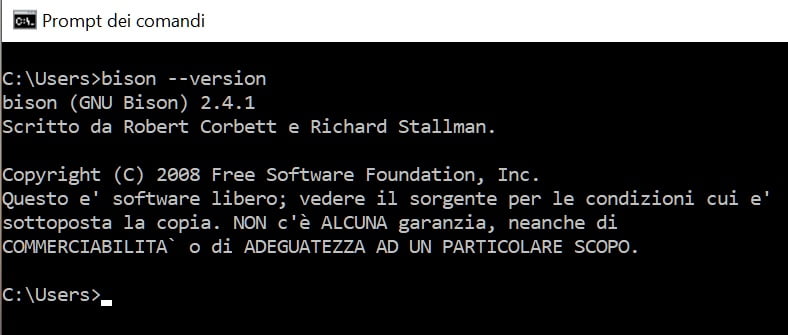
flex –version
Premi Invio, in risposta se otterrai indicazioni, circa la versione di flex installata, significa che il generatore di scanner è stato installato correttamente, come mostrato in figura:

3. Le espressioni regolari
Adesso dobbiamo prendere in considerazione un oggetto, molto usato dagli sviluppatori, che è conosciuto come “espressione regolare”. Sicuramente avrai già sentito parlare di espressioni regolari oppure le hai già usate in passato.
Sono utilizzate per ricercare e sostituire porzioni di testo in stringhe, per cui sono ampiamente usate da tutti i linguaggi di programmazione, non solo, vengono ad esempio utilizzate anche dagli editor di testo per ricercare e sostituire stringhe nel codice sorgente.
Se sei un abile utilizzatore, delle espressioni regolari, puoi anche tralasciare la lettura di questo paragrafo e passare al successivo, altrimenti ti consiglio di proseguire, in quanto, questo tipo di oggetto inventato nel lontano 1950 e attualmente ancora insostituibile, rappresenta uno dei pilastri fondamentali della programmazione.
Ad ogni modo, in questo articolo, non tratterò le espressioni regolari nel suo complesso, ci sono libri interi che trattano l’argomento, ma vedremo solo l’aspetto riguardante la ricerca di stringhe all’interno di flussi di dati, come potrebbe essere, ad esempio, un file di testo.
Quindi, senza entrare troppo nello specifico, le espressioni regolari verranno utilizzate da Flex, cioè dal generatore di scanner, per individuare i TOKEN, cioè le keywords del nostro linguaggio, all’interno di uno script o file sorgente.
La cosa sembra complessa ma non lo è affatto. Quando vedrai come lavora Flex ti renderai subito conto della semplicità delle espressioni regolari e del loro irrinunciabile vantaggio offerto allo sviluppo.
Ti consiglio di dare un’occhiata a questo video tutorial, non è necessario, ma avrai già da subito l’idea, di cosa sono le espressioni regolari e di come utilizzarle.
4. La struttura dell’interprete
Prima di passare alla fase di implementazione del lessico e della grammatica del linguaggio, devi scaricare un ultimo pacchetto software. Riguarda un file, compresso che contiene la struttura dell’interprete, composta da cartelle e file, già preparate ad hoc, per metterti nelle condizioni di capire subito, aprendo opportuni file che ti spiegherò, come avviene la progettazione vera e propria dell’interprete.
Quindi, scarica da questo link, ed estrai il contenuto, cioè l’interprete, nella posizione sul pc che ritieni più opportuna, già compilabile ed eseguibile. Nei paragrafi successivi, ti spiegherò passo passo, il contenuto dei file e come personalizzare il lessico e la grammatica, programmando opportunamente il lexer e il parser.
Al termine del download, troverai una cartella nominata “linguaggio”, così composta:
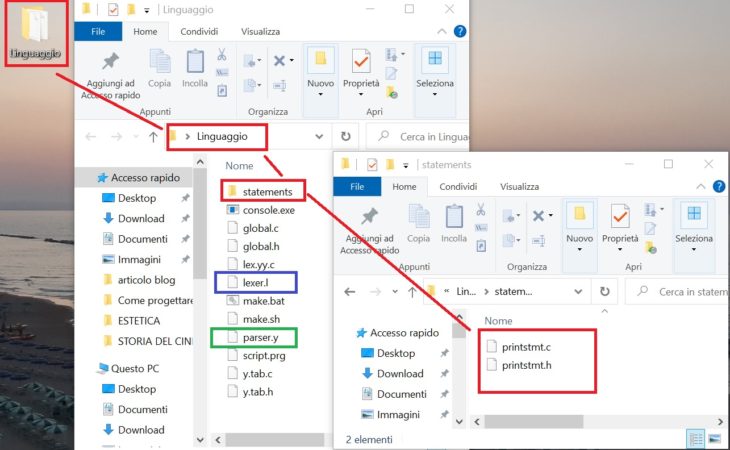
Tanto per completezza e, sicuramente lo avrai già notato, io sto utilizzando Windows 10, ed ho decompresso il file linguaggio.zip sul mio desktop. Tengo a precisare, come ho ribadito già precedentemente, che tutto quello che farai con questo progetto in Windows 10 è applicabile anche a qualsiasi altra distribuzione Linux.
5. Implementazione del lessico
Adesso entra in gioco Visual Studio Code. Quindi, non devi fare altro che aprire l’editor della Microsoft, e cliccare sulla voce “File” del menù principale e successivamente sulla voce “Open Folder”, scegli la cartella “linguaggio” e clicca su “Selezione cartella”.
Il risultato è mostrato in figura:
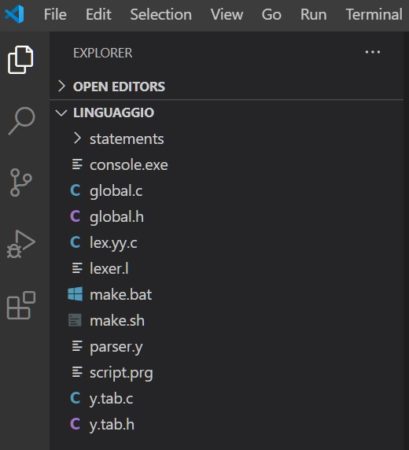
nel frame di sinistra, noterai elencato tutto il contenuto della cartella “linguaggio”, adesso dovrai aprire il file “lexer.l”, cliccandoci sopra, che ti permetterà di programmare lo scanner. Questo file successivamente verrà dato in pasto a Flex, che genererà lo scanner perfetto per il tuo primo interprete.
Questo file è composto da quattro sezioni. Nella prima sezione, cioè quella racchiusa tra i caratteri “%{“ e “%}”, sono presenti solo istruzioni di inclusione di file header della libreria standard di C. in questa sezione per il momento non apporterai nessuna modifica.
Nella seconda sezione, cioè quella racchiusa tra i caratteri “%}” e “%%”, sono presenti istruzioni già più interessanti della prima. Ora, dai un’occhiata al seguente codice:
Number ([0-9]+)|([0-9]+\.[0-9]+)|(\.[0-9]+)
Argument (([-*./|a-zA-Z])|([-*./|_a-zA-Z][-*./|_a-zA-Z0-9]+))
String \"(([^\"]*)|([\!]*))\"
Identifier @?(([a-zA-Z])|([_a-zA-Z][_a-zA-Z0-9]+))Infatti, queste istruzioni non hanno bisogno di commenti, si capisce subito leggendo gli identificatori, che tutto quello che segue la dicitura Number, rappresenta l’espressione regolare che serve allo scanner per identificare un numero presente all’interno del flusso dati ricevuto dallo scanner stesso o presente all’interno dello script di comandi. Anche qui, e giusto per richiamare quanto detto precedentemente con le espressioni regolari, non devi apportare nessuna modifica. Ad ogni modo, quando viene identificato un numero lo scanner ritorna il token NUMBER al parser.
La stessa cosa vale per l’identificatore String, la cui espressione regolare, da indicazioni allo scanner per ricercare eventuali stringhe, contenute nel flusso dati o nel nostro script di comandi. Questo identificatore ritorna il token STRING al parser.
La stessa cosa vale per l’identificatore Argument, la cui espressione regolare, da indicazioni allo scanner per ricercare eventuali argomenti o parametri, passati ai comandi che creeremo, contenute nel flusso dati, o nel nostro script di comandi. Questo identificatore ritorna il token ARGUMENT al parser.
La stessa cosa vale per l’identificatore Identifier, la cui espressione regolare, da indicazioni allo scanner per ricercare eventuali identificatori, ad esempio nomi di variabili o quant’altro, passati ai comandi che creeremo, contenute nel flusso dati o nel nostro script di comandi. Questo identificatore ritorna il token IDENTIFIER al parser.
Ora, guarda le righe di codice seguenti:
A [aA]
B [bB]
C [cC]
D [dD]
E [eE]
…
…Queste rendono il nostro interprete No Case Sensitive. Cioè i comandi che creeremo, e tutto ciò che scriveremo nei nostri script di comandi, potrà essere scritto indifferentemente in minuscolo o maiuscolo, e di conseguenza lo scanner individuerà senza problemi, ad esempio, il comando PRINT, in ognuna di queste forme: PRINT che Print sia pRiNt, ecc…
Nella terza sezione, cioè quella che contiene le seguenti istruzioni:
P}{R}{I}{N}{T} { return PRINT; }
{C}{L}{E}{A}{R} { return CLEAR; }
{H}{E}{L}{P} { return HELP; }
{Q}{U}{I}{T} { return QUIT; }
{E}{X}{I}{T} { return EXIT; }
{D}{I}{R} { return DIR; }
{C}{L}{S} { return CLS; }
"(" { return OPENBRACKET;}
")" { return CLOSEBRACKET;}
"," { return COMMA;}contiene l’implementazione dei comandi: PRINT, CLEAR, HELP, QUIT, EXIT, DIR, CLS. Come puoi notare a destra di ogni comando e specificato tra parentesi graffe il TOKEN che verrà inviato al parser, cioè a Bison, e vedremo successivamente come il parser verificherà la grammatica del comando, eseguendo il codice associato.
Nella quarta sezione, cioè quella che contiene le seguenti istruzioni:
int main(int argc, char **argv) {
++argv;
yyin = stdin;
if ( --argc > 0 ) {
// il flusso dati è lo script
prompt = "";
yyin = fopen(argv[0], "r");
} else {
// il flusso dati è la shell di comandi
printf("%s", consoleMex);
printf(prompt);
}
while(true) {
if (yyparse() != 0) {
// richiamata yyerror, se nessun TOKEN viene individuato
// parliamo del classico syntax error
}
}
}
int yywrap(void) {
return 0;
}
int yyerror(const char *errormsg) {
fprintf(stderr, "%s\n", errormsg);
exit(1);
}è la parte di codice C, che mette in moto lo scanner. Stiamo parlando di quella parte di codice che scansiona il flusso dati, attraverso la funzione yyparse(), cioè il nostro script di comandi, riconosce i TOKEN specificati nella terza sezione, e li invia al parser. Nel prossimo paragrafo vedremo come, quest’ultimo riconosce la grammatica di un comando, e ne esegue il codice C associato.
Prima di passare alla descrizione del parser, voglio fare una precisazione. La parte di codice che segue l’istruzione yyin = stdin; serve ad eseguire i comandi o le istruzioni che creeremo, in due ambienti diversi e precisamente:
a) Se quando esegui l’interprete passi come argomento un file, il tuo script di comandi, allora lo scanner leggere lo script e lo considererà come flusso dati da verificare e analizzare.
b) Se invece quando esegui l’interprete non passi nessun argomento, allora lo scanner aprirà una shell di comandi, e tutto ciò che digiterai da tastiera verrà verificato dallo scanner. Di conseguenza verrà visualizzata una shell di comandi, il nostro terminale con un messaggio iniziale, e da lì in poi tutto quello che digiti verrà processato dallo scanner e considerato come flusso dati in ingresso da gestire.
Ribadisco che anche in questa sezione, per il momento, non devi apportare nessuna modifica.
6. Implementazione della grammatica
Adesso entriamo nel vivo del discorso, stiamo per vedere come lavora un parser. Per il momento, sempre nel frame di sinistra, apri il file “parser.y” cliccandoci sopra. Questo file è composto da varie sezioni, ma la più interessante è questa:
commands:
printstmt
| dirstmt
| helpstmt
| quitstmt
| clsstmt
| clearstmt
;gli identificatori che seguono la direttiva “commands”, non sono altro che nomi associati alla grammatica di ogni comando creato. Per esempio, al comando PRINT ho associato il nome printstmt dove stmt sta per statement (istruzione), ma tu puoi dare il nome che desideri. Per cui, il comando DIR (lista di cartelle e file, comando molto conosciuto… che avrai usato mille volte) ho associato il nome dir+stmt, ecc…
Ogni altro comando deve essere aggiunto in questa sezione specificandone il nome che assocerai alla grammatica, ma lo vedremo tra un po’.
Tutto il codice che segue la dichiarazione “commands” è la grammatica, cioè la sintassi vera è propria del comando, ad esempio:
printstmt:
PRINT STRING {
printStatement($2);
if(strlen(prompt) > 0) printf("\n");
}
;Questo codice, è di una semplicità disarmante, ma vediamo nel dettaglio cosa fa. Innanzitutto la dichiarazione “printstmt:” sta ad indicare che il codice che segue è associato alla direttiva “printstmt” richiamata in “commands” e verificata ciclicamente tutte le volte che viene ripetuta all’interno dello script o digitato nella shell dei comandi.
I token PRINT STRING, specificano la grammatica del comando PRINT. Cioè il comando PRINT è costituito dal token PRINT + un argomento, che in questo caso è una stringa, e cioè STRING. Ad esempio, potremmo digitare qualcosa del genere: print “Hello world”.
Il codice che segue la grammatica di PRINT, cioè: printStatement($2); esegue la funzione printStatement che troverai nella sottocartella “statements” posizionata sotto “linguaggio”, ricordi?
Solo una precisazione, circa l’argomento $2, della function printStatement. Nella dichiarazione della grammatica del comando PRINT e cioè: PRINT STRING, il parser associa ad ogni TOKEN presente, da sinistra verso destra, un progressivo preceduto dal simbolo $. In questo caso a PRINT è associato $1 e a STRING è associato $2. Questo significa che quando viene richiamata la function printStatement, il parametro $2 conterrà la stringa passata come argomento a PRINT, e così via, per cui potremmo avere anche un $3, un $4 e così via. Parliamo di parametri, che compongono la grammatica del comando e che potrebbero contenere stringhe, numeri e quant’altro.
Torniamo al comando PRINT. In questo caso, e per ogni comando, creerai due file nella cartella “statements”, è cioè printstmt.c e printstmt.h, il primo contiene il codice vero è proprio del comando print mentre il secondo non è altro che il file header, così come prevede il linguaggio C.
A questo punto vediamo cosa contiene il file printstmt.c:
#include <stdio.h>
#include <stdlib.h>
#include "../global.h"
#include <string.h>
#include "printstmt.h"
void printStatement(const char* stringLiteral) {
printf("%s", stringLiteral);
}Qui vediamo che, una volta verificata la grammatica, il parser esegue questa porzione di codice:
void printStatement(const char* stringLiteral) {
printf("%s", stringLiteral);
}E il parametro stringLiteral, contiene il contenuto passato dall’argomento $2. Pertanto ogni comando sarà composto esattamente come PRINT. Per cui il comando PRINT non fa altro che stampare a video il contenuto passato dal token STRING e associato a $2 dal parser con questa istruzione: printf(“%s”, stringLiteral);
A te, lascio il compito di vedere cosa è stato fatto per gli altri comandi che troverai descritti in parser.y, per quanto riguarda la grammatica e, nei relativi file contenuti nella sottocartella “statements”, per quanto riguarda l’azione associata ad ogni comando.
7. Compilazione dell’interprete
il compito legato alla programmazione dei comandi e della relativa shell è terminato, adesso dobbiamo vedere in esecuzione il nostro interprete ed iniziare ad eseguire qualche comando da shell o da file script.
La prima operazione necessaria da effettuare è compilare il nostro interprete, poi devono essere generati anche lo scanner e il parser. Ricordi quanto detto precedentemente con Flex e Bison?
A tal proposito ho implementato un file make sia per windows che per ambiente Linux. I due file li trovi sotto la root del progetto e cioè la cartella “linguaggio”.
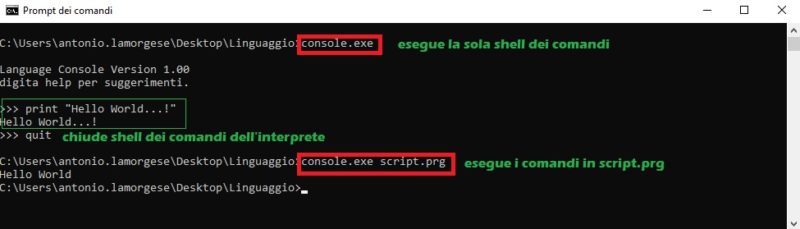
Quindi, basta lanciare, da prompt dei comandi o da terminale linux, rispettivamente il file make.bat per windows e make.sh per linux. Questo è tutto, il file make genererà un eseguibile chiamato “console.exe”, rinominabile a tuo piacimento, che è l’interprete. Se esegui console.exe senza argomenti apre il solo prompt dei comandi dell’interprete e tutto ciò che digiti verrà direttamente interpretato dallo scanner a video, mentre se passi a console.exe un file, come ad esempio il file script.prg, tutto quanto contenuto all’interno dello script verrà interpretato dallo scanner.
Va precisato che, volutamente, tutti gli altri comandi, parlo di: CLEAR, HELP, QUIT, EXIT, DIR, CLS, non hanno un corrispondente file “.c” nella cartella “statements”. Questo perché non sempre è necessario associare l’azione di un comando in un file separato. Ma come per questi comandi ho preferito associare l’azione del comando, direttamente all’interno della grammatica, e cioè nel file parser.y. Questa tecnica è consigliabile quando l’azione da associare è eseguibile con poche righe di codice.
Tanto per chiarezza ti ripropongo il codice associato al comando DIR:
dirstmt:
DIR ARGUMENT {
if(strlen(prompt) > 0) {
char *dest;
char *src;
strcpy(dest, "dir ");
strcpy(src, $2);
strcat(dest, src);
system(dest);
}
}
| DIR {
if(strlen(prompt) > 0) system("dir *.*");
}
;Come puoi vedere, questo comando agiste solo all’interno della shell, questo si evince dal fatto che le istruzioni sono tutte inserite all’interno di: if(strlen(prompt) > 0). Il comando non fa altro che eseguire il comando “dir *.*” se non ha argomenti, altrimenti esegue DIR con l’argomento contenuto all’interno della variabile $2. $2 potrebbe essere qualsiasi cosa, ad esempio, *.prg, cioè qualsiasi cosa digitata da te nella shell. Il tutto è eseguito attraverso la function “system” della libreria standard di C, che consente di lanciare comandi del sistema operativo.
Da notare che il comando, nel file parser.y, ha due varianti della grammatica, cioè DIR ARGUMENT e DIR. Le due grammatiche sono interpretate ed associate dal carattere “|”, vale a dire o questa grammatica “DIR ARGUMENT” o quest’altra “DIR“.
8. Conclusione
Cercherò di riepilogare il processo di creazione di un altro comando. Quindi, come prima cosa devi modificare il file lexer.l, ed aggiungere, subito dopo questa istruzione “{C}{L}{S} { return CLS; }” il tuo comando, ad esempio: {M}{I}{O}{C}{O}{M}{A}{N}{D}{O} { return MIOCOMANDO; }.
Successivamente, devi modificare il file parser,y e, aggiungere subito dopo la seguente istruzione “| clearstmt”, a riga 37, la dichiarazione che identificherà lo statement relativo al token MIOCOMANDO, e cioè, “| miocomandostmt” (attenzione le virgolette non devono essere incluse).
Aggiungi, prima del carattere “%%” di fine file, un blocco identico a questo:
miocomandostmt:
MIOCOMANDO {
// istruzioni in pura filosofia C
}
;nel caso in cui hai deciso di apportare l’azione corrispondente alla grammatica di MIOCOMANDO in un file .c separato, allora devi aggiungere due file nella cartella “statements”, e cioè: miocomandostmt.c e miocomandostmt.h, ed aggiungere dopo la riga gcc -w -c statements/printstmt.c -o statements/printstmt.o, la seguente istruzione: gcc -w -c statements/miocomandostmt.c -o statements/miocomandostmt.o, e modificare l’istruzione: gcc -w -o console.exe global.o statements/printstmt.o y.tab.o lex.yy.o, in questo modo: gcc -w -o console.exe global.o statements/printstmt.o statements/miocomandostmt.o y.tab.o lex.yy.o lasciando inalterato il resto.
Le stesse modifiche vanno apportate anche al file make.sh, per ambiente linux, alla stessa stregua di quanto fatto in make.bat. A questo punto non ti resta che eseguire da prompt dei comandi “make.bat” o “make.sh” in Linux, come mostrato in figura:
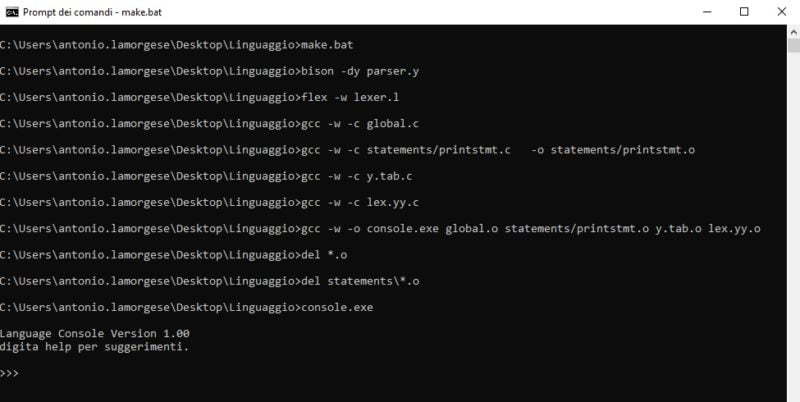
A termine esecuzione del file make, si aprirà automaticamente l’interprete “eseguendo il file “console.exe”, digita il tuoi comandi direttamente da shell, oppure con console.exe script.prg, farai eseguire all’interprete i comandi memorizzati all’interno del file script.prg, come mostrato in figura:
Spero di esserti stato di aiuto e di aver fugato ogni dubbio su un argomento relativamente ostico.

Desideri acquisire nuove competenze?
l'opportunità di acquisire nuove competenze e di
migliorare il tuo curriculum professionale.
Clicca qui per seguire le prime lezioni gratuite online