Speech to Text (STT) e Text to Speech (TTS) – La sintesi vocale in Python
Le funzionalità Speech to Text e Text to Speech, cioè tradurre voce parlata in testo e viceversa, sono molto richieste in diversi software. Con Python e due librerie gratuite è possibile.
di Antonio Lamorgese
Quando sentiamo parlare di Speech To Text (STT) e Text To Speech (TTS) abbiamo a che fare, sempre, con un sistema di riconoscimento vocale. Cioè, un vero e proprio strumento di sintesi vocale, questa volta, realizzato in Python con pochissime righe di codice.
I sistemi di riconoscimento vocale, sono una caratteristica molto richiesta in varie tipologie di software. Molto spesso, vengono utilizzati per automatizzare applicazioni in contesti dove all’utente è necessario fornire indicazioni specifiche e ripetitive. Ad esempio, nei call-center, per implementare sistemi di dettatura automatica, che consentono di dettare interi discorsi al computer.
Implementare da zero una funzionalità di riconoscimento vocale può rivelarsi un’impresa molto complessa. Per fortuna, grazie a Python e a tre librerie gratuite, SpeechRecognition, pyttsx3 e pyaudio, tutto questo è realizzabile in brevissimo tempo e con pochissime righe di codice.
In questa guida, avrai modo di capire come implementare da zero un sistema di riconoscimento vocale. Cioè, uno strumento di conversione da voce parlata a testo e da testo a voce parlata.
LEGGI ANCHE: I migliori Text To Speech online per convertire testo in voce parlata.
Indice del Post...
1. Installare i moduli Python necessari
Come in ogni progetto Python, per implementare caratteristiche particolari ad un software, è necessario installare delle librerie o moduli. Le librerie in questione sono SpeechRecognition, pyttsx3 e pyaudio. Per utilizzarle, quindi, devi prima installarle sul tuo computer. L’installazione è semplicissima, basta eseguire questo codice da prompt dei comandi o da terminale Linux:
pip install speechrecognition pip install pyaudio pip install pyttsx3
1.1 Da Voce parlata a Testo
Nello specifico, la libreria SpeechRecognition, ti permetterà di convertire la voce parlata in testo. Nell’esempio proposto in questa guida, per la conversione, useremo le API di Google. Ad ogni modo, la libreria supporta un numero considerevole di API utilizzate per il riconoscimento vocale. Negli esempi scaricabili dalla home page di PyPi è possibile ricercare la libreria SpeechRecognition e provare, copiando e incollando il codice, all’interno di IDLE, l’interfaccia visuale fornita con Python, il codice fornito dallo sviluppatore della libreria.
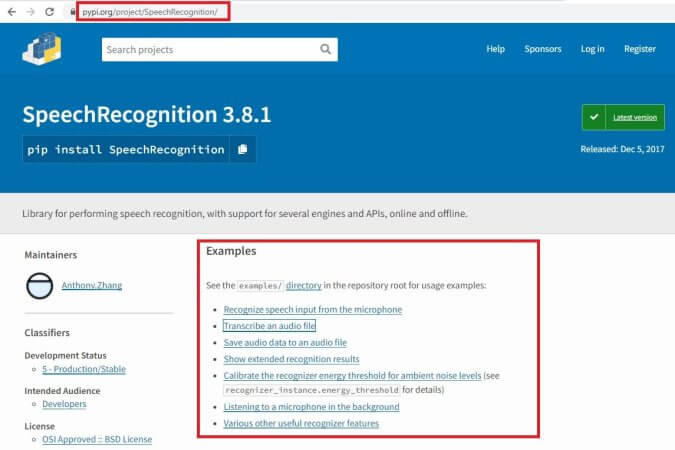
Ad esempio, con questo codice, puoi vedere subito come convertire la tua voce parlata in formato testo e memorizzare la conversione in una variabile:
import speech_recognition as sr
# obtain audio from the microphone
r = sr.Recognizer()
with sr.Microphone() as source:
print("Say something!")
audio = r.listen(source)
# recognize speech using Google Speech Recognition
try:
# for testing purposes, we're just using the default API key
# to use another API key, use `r.recognize_google(audio, key="GOOGLE_SPEECH_RECOGNITION_API_KEY")`
# instead of `r.recognize_google(audio)`
print("Google Speech Recognition thinks you said " + r.recognize_google(audio))
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
In questo breve video tutorial puoi vedere come realizzare un convertitore Speech To Text con speechrecognition e le utilizzatissime API, per il riconoscimento vocale, di Google (Google text-to-speech API).
1.2 Text To Speech (TTS) – Da Testo a Voce parlata
Alla stessa stregua di quanto hai fatto con la libreria speechrecognition puoi compiere l’operazione inversa. Cioè, copiando e incollando questo codice, puoi convertire un testo in voce parlata. La libreria da utilizzare è pyttsx3, reperibile anch’essa sul portale PyPi:
import pyttsx3
engine = pyttsx3.init() # object creation
# RATE
rate = engine.getProperty('rate') # getting details of current speaking rate
print (rate) #printing current voice rate
engine.setProperty('rate', 125) # setting up new voice rate
# VOLUME
volume = engine.getProperty('volume') #getting to know current volume level (min=0 and max=1)
print (volume) #printing current volume level
engine.setProperty('volume',1.0) # setting up volume level between 0 and 1
# VOICE
voices = engine.getProperty('voices') #getting details of current voice
#engine.setProperty('voice', voices[0].id) #changing index, changes voices. o for male
engine.setProperty('voice', voices[1].id) #changing index, changes voices. 1 for female
engine.say("Hello World!")
engine.say('My current speaking rate is ' + str(rate))
engine.runAndWait()
engine.stop()
# Saving Voice to a file
# On linux make sure that 'espeak' and 'ffmpeg' are installed
engine.save_to_file('Hello World', 'test.mp3')
engine.runAndWait()
Anche per pyttsx3 è bene seguire questo breve video tutorial dove avrai modo di apprezzare con quanta semplicità puoi realizzare un convertitore Text To Speech con la libreria pyttsx3.
Leggi anche: Trasforma qualsiasi testo in video in 5 semplici passaggi

Desideri acquisire nuove competenze?
l'opportunità di acquisire nuove competenze e di
migliorare il tuo curriculum professionale.
Clicca qui per seguire le prime lezioni gratuite online