Ecco come aumentare le prestazioni delle Query di Microsoft SQL Server
Alcuni semplici trucchi, poco conosciuti, per migliorare le prestazioni delle Query di Microsoft SQL Server.
di Antonio Lamorgese
Dopo un breve periodo di utilizzo di un database SQL Server da parte di un applicativo spesso si nota un peggioramento dei tempi di esecuzione delle Query di Microsoft SQL Server che peraltro interessano qualunque tipo di database relazionale. Avendo questi database una struttura a tabelle logica e non fisica, cioè, i dati presenti nelle tabelle non sono memorizzati su file singoli, ma è come se ogni dato fosse marcato appartenente a quel database e ad una determinata tabella. Il tutto gestito da Microsoft SQL Server in modo del tutto trasparente all’utente. Non è raro notare un calo delle prestazioni di esecuzione delle Query a distanza di tempo dal primo utilizzo del database.
A tal proposito, esistono delle tecniche che ogni programmatore deve mettere in atto, periodicamente, sul database per migliorare le prestazioni in fase di esecuzione di ogni Query. Questo eviterà lunghe attese, ma soprattutto, errori dovuti a Timeout durante l’estrapolazione dei dati tramite Query SQL. Più avanti, nella guida, ti spiegherò passo-passo, cosa fare e come gestire un database SQL effettuando specifiche operazioni dalla console di Microsoft SQL Server Management Studio. Tutto quello che troverai scritto in questa guida fa riferimento al RDBMS Microsoft Sql Server. In particolare alla versione SQL Server Express rilasciata gratuitamente dalla Microsoft.

Indice del Post...
1. L’importanza del campo IDENTITY
Ogni tabella, in SQL Server, ha bisogno, per modificare e recuperare più velocemente i dati, di un campo di tipo int con la proprietà identity attivata e su cui, solitamente, è associata anche una chiave primaria. Senza una chiave primaria, SQL Server, non riuscirà ad individuare velocemente il record o i record da aggiornare. Si avrà così un aumento dei tempi di aggiornamento dei dati con probabile errore di timeout. È buona abitudine inserire sempre un campo di nome ID di tipo INT e con la proprietà IDENTITY attivata. Questo campo, inoltre, è obbligatorio impostarlo anche come chiave primaria.
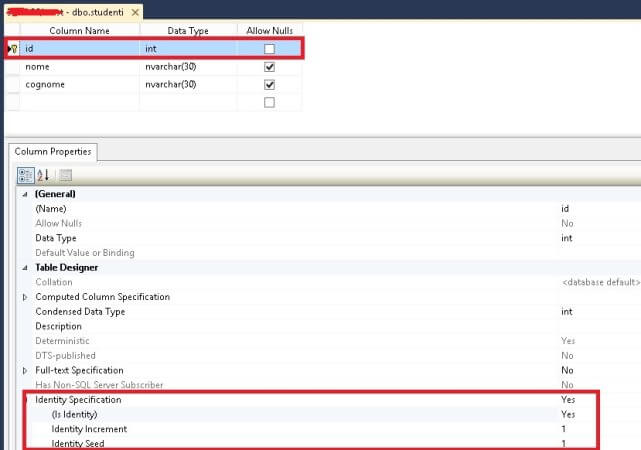
Sarà cura di SQL Server popolare la colonna IDENTITY e, una volta creata questa colonna, il programmatore non dovrà preoccuparsi più di nulla. In altri tipi di database relazionali la colonna IDENTITY può essere paragonata a campi ad AUTO INCREMENTO.
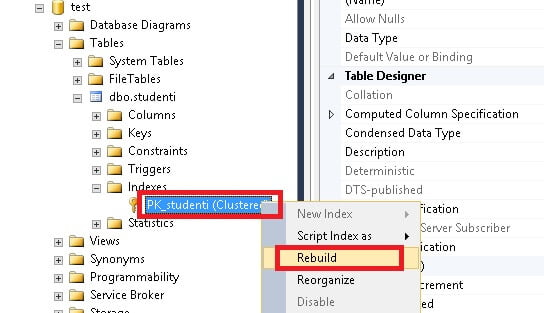
Inoltre, è sempre meglio effettuare, periodicamente, un’operazione di rebuild della chiave primaria impostata su un campo identity. Questa operazione è effettuabile da SQL Server Management Studio espandendo la voce indexes e cliccando con tasto destro del mouse sulla chiave primaria che il sistema ha creato automaticamente durante la fase di impostazione della voce identity.
2. La clausola WITH (NOLOCK)
Molti sviluppatori, a seguito di questo improvviso aumento dei tempi di esecuzione di una Query perdono tempo prezioso a cercare in rete eventuali soluzioni. Ma quello che bisogna fare, a volte, è racchiuso nella conoscenza di poche semplici operazioni. SQL Server, include già procedure di ottimizzazione automatiche. Ma il programmatore in fase di progettazione di una Query SQL deve sapere come e quali clausole utilizzare per ridurre al massimo i tempi di esecuzione di una Query.
È buona norma, infatti io la utilizzo sempre, inserire la clausola WITH(NOLOCK) subito dopo il nome della tabella in un comando SELECT.
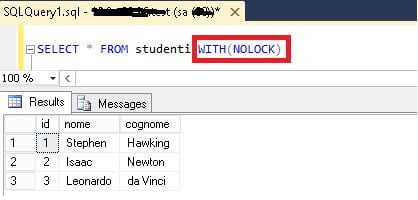
Questa clausola, velocizza notevolmente i tempi di esecuzione di una Query escludendo qualsiasi tipo di blocco in fase di lettura dei dati. Questo tipo di approccio non è sempre applicabile, in quanto SQL Server, potrebbe restituire dati incongruenti specialmente quando si ha a che fare con tabelle che subiscono innumerevoli modifiche nell’arco di pochi minuti. Ma parliamo di situazioni molto rare. Nella stragrande maggioranza dei casi la clausola WITH(NOLOCK) è sempre consigliabile.
3. La ricostruzione degli indici delle tabelle
Come l’indice di un libro anche SQL Server utilizza gli indici come strumento per recuperare velocemente informazioni da un database. Con il passare del tempo e con l’aumento dei record contenuti nel database gli indici subiscono una forte deframmentazione. Cioè SQL Server farà sempre più fatica a reperire informazioni pur consultando l’indice. È un po’ quello che succede con gli hard disk quando si deframmentano. A questo punto è necessario effettuare prima un’operazione di deframmentazione cliccando sulla voce Reorganize e successivamente un Rebuild dell’indice. Queste operazioni vanno effettuate periodicamente su tutti gli indici delle tabelle di un database.
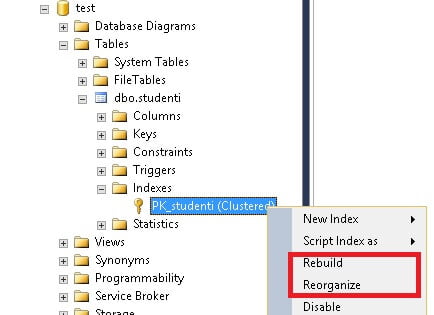
SQL Server, prima di riorganizzare un indice e quindi di deframmentarlo, restituisce al programmatore la percentuale di deframmentazione che l’indice presenta in quel momento. È preferibile procedere con la deframmentazione se la percentuale supera il 30%. Ad ogni modo la decisione è delegata allo sviluppatore che potrà in ogni caso, indipendentemente dal grado di deframmentazione dell’indice, decidere se procedere o meno.
4. Il livello di isolamento di una transazione
In SQL SERVER, tutto il codice eseguito da una Stored Procedure passa per 5 tipi di isolamento previsti. Cosa significa. Significa che avendo a che fare con sistemi in multiutenza, è possibile che i dati elaborati da una Stored Procedure vadano in conflitto con i dati modificati da altre Stored Procedure invocate in tempi diversi da altri utenti. Per questo motivo, SQL SERVER, mette a disposizione dello sviluppatore 5 tipi di isolamento previsti.
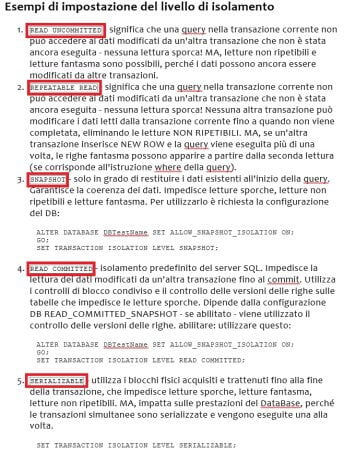
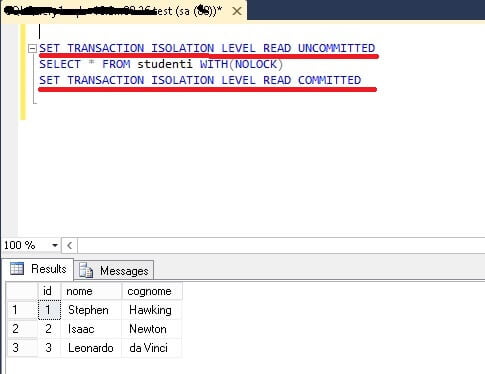
Logicamente, più alto è il livello di isolamento più tempo e risorse vengono richieste al sistema per elaborare e gestire i dati. In genere, salvo casi eccezionali, è consigliabile specificare il livello di isolamento “READ UNCOMMITTED” prima di ogni altra istruzione presente in una Stored Procedure e, reimpostare il livello di isolamento “READ COMMITTED” come ultima istruzione in una Stored Procedure.
5. Come utilizzare il SET NOCOUNT
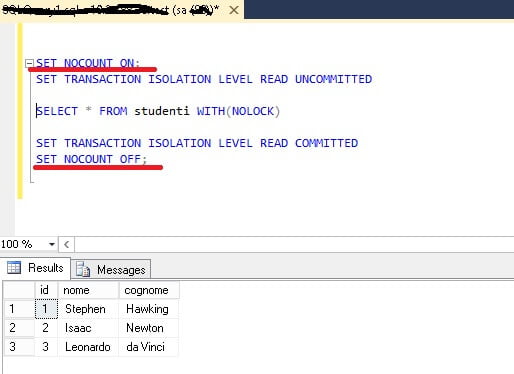
Per default il SET NOCOUNT è impostato a OFF. Questo significa che ogni volta che viene eseguita una Query, SQL Server, elabora anche il numero di righe interessate da questa Query SQL. Questo può essere utile quando una Query viene elaborata all’interno della console di comandi di SQL. Ma quando una Query viene invocata da un software applicativo il risultato fornito da NOCOUNT non è di alcuna utilità. Quindi, è consigliabile attivare il NOCOUNT e disattivarlo una volta terminata l’esecuzione della Query SQL.
6. La clausola OPTION FAST
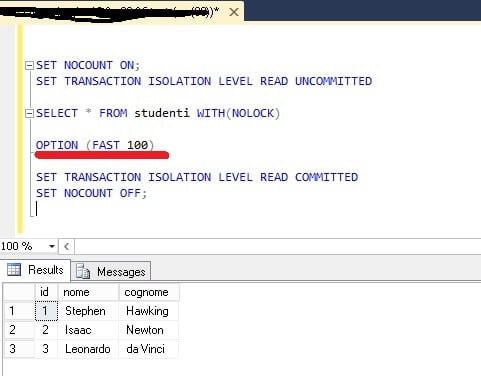
Abbiamo assodato che per eseguire una Query SQL, il server impiega del tempo. Tempo che è possibile ridurre utilizzando, oltre alle clausole viste precedentemente, un’ultima opzione. Questa clausola è OPTION (FAST N) dove “N” è il numero di righe, indicate dallo sviluppatore, per recuperare velocemente i record quando è possibile risalire a priori ai record che la Query restituirà. Questo tipo di approccio velocizzerà enormemente la Query fornendo rapidamente il result set di dati in tempi record.
7. Ripristino di una tabella
Può capitare che pur applicando tutti i consigli visti precedentemente la Query continua ad essere eseguita con tempi fuori dal normale. In questo caso, una volta individuata la tabella incriminata e soprattutto per tabelle con molti record, conviene ricreare la tabella e ripopolarla nuovamente. Tranquillo non perderai nulla. L’operazione è sicura ed è eseguibile in tempi piuttosto brevi. Quindi, Cosa devi fare? Beh, innanzitutto rinomina la tabella da ripristinare aggiungendo il suffisso OLD al nome, ad esempio, la tabella studenti diventerà studenti-OLD. Ora, crea una nuova tabella con la stessa struttura, indici compresi, della precedente dandole il nome originario ma aggiungendo il suffisso NEW, per esempio studenti diventerà, studenti-NEW.
Ora, con questa Query SQL, non devi fare altro che riversare tutti i record da studenti-OLD a studenti-NEW e rinominare studenti-NEW in studenti.
INSERT INTO studenti-NEW SELECT * FROM studenti-OLD EXEC sp_rename ‘studenti-NEW’, ‘studenti’
Leggi anche: Il segreto per scrivere Query SQL
8. Pianificazione di un Backup del database
Tramite l’operazione di Backup, un programmatore, non mette solo al sicuro i dati da eventuali crash di sistema, ma compie anche operazioni di manutenzione e miglioramento del database in questione. Infatti, insieme alla procedura di backup, SQL Server, effettua anche una compattazione e una deframmentazione del database. Operazione di notevole importanza per il mantenimento dell’efficienza del database. Effettuare il backup di un database con SQL Server è un’operazione molto semplice, basta seguire i passi proposti dal Wizard di SQL Server Management Studio. È possibile anche creare un job per pianificare, a intervalli prestabiliti, l’esecuzione di backup lasciando a SQL Server il pieno controllo di questa attività. Solo che questa possibilità è offerta dalle versioni di SQL Server dalla Professional in poi. La versione Express, cioè quella gratuita, non dà la possibilità di creare Job e pianificare operazioni programmate. È possibile, però, creare un file batch copiare e incollare, le istruzioni di seguito modificando i parametri servername, databasename e il filepath, all’interno del file batch, e pianificare l’esecuzione di questo file batch, in giorni prestabiliti, sfruttando il Task Scheduler di Windows.
SqlCmd -E -S servername -Q "BACKUP DATABASE databasename TO DISK ='filepath\filename.bak'"
Leggi anche: Come installare MySQL Server su Raspberry Pi 4

Desideri acquisire nuove competenze?
l'opportunità di acquisire nuove competenze e di
migliorare il tuo curriculum professionale.
Clicca qui per seguire le prime lezioni gratuite online